
When updating reporting solutions or building an enterprise data warehouse, the goal is to optimize information organization. To do this you will need to develop a data model. While the relational model is a commonly used solution, the lesser known data vault model may provide a better result for information organization.
Both solutions achieve the same goal of feeding the information into a data warehouse to produce results. However, there are differences between the models, and determining what solution best fits your needs is in imperative step in building a successful enterprise data warehouse.
This post will overview the data vault model and how, if used correctly, it can optimize your company’s data.
Intro to Data Vault
The concept of Data Vault was initially introduced to model data for storage in a warehouse for achieving the following goals:
- Provide storage for historical data coming from multiple operational systems
- Provide auditing and lineage or traceability of all data
- Enable faster data load through parallelization
- Provide flexibility for changing data model when there is change in business processes
- Store a “single version of facts”
- Hybrid model of the best parts of 3rd Normal Form (3NF) and star schema.
Data Vault is a hybrid solution that combines data normalization and dimensional modeling.
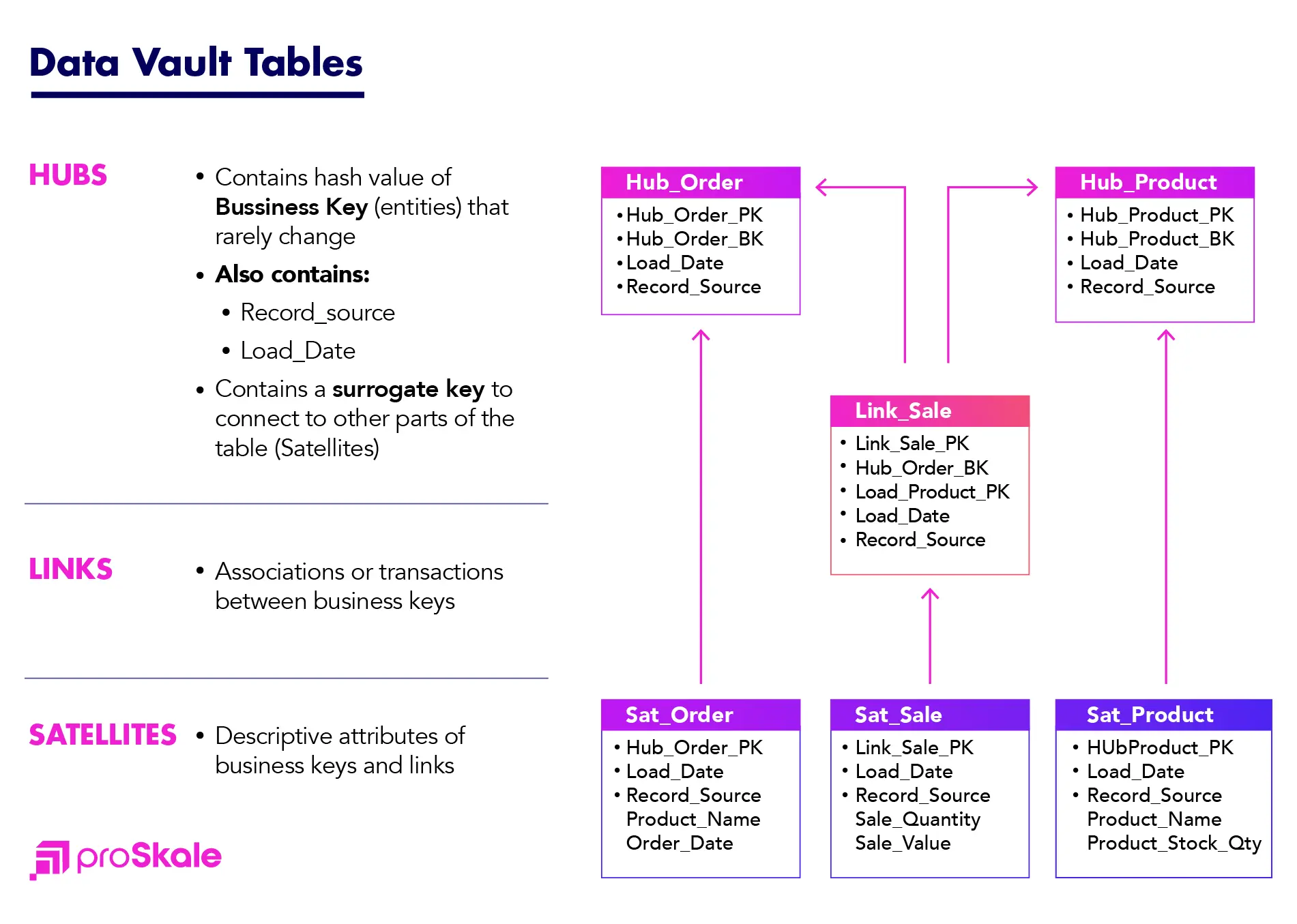
Data Vault provides flexibility for change by separating out business keys that uniquely identify each business entity and do not mutate, and the associations between them and their attributes. The business keys are stored in tables called Hubs.
Relationships between business keys (Hubs) are also stored in tables and are called Links.
The attributes are stored in one or multiple tables called Satellites.
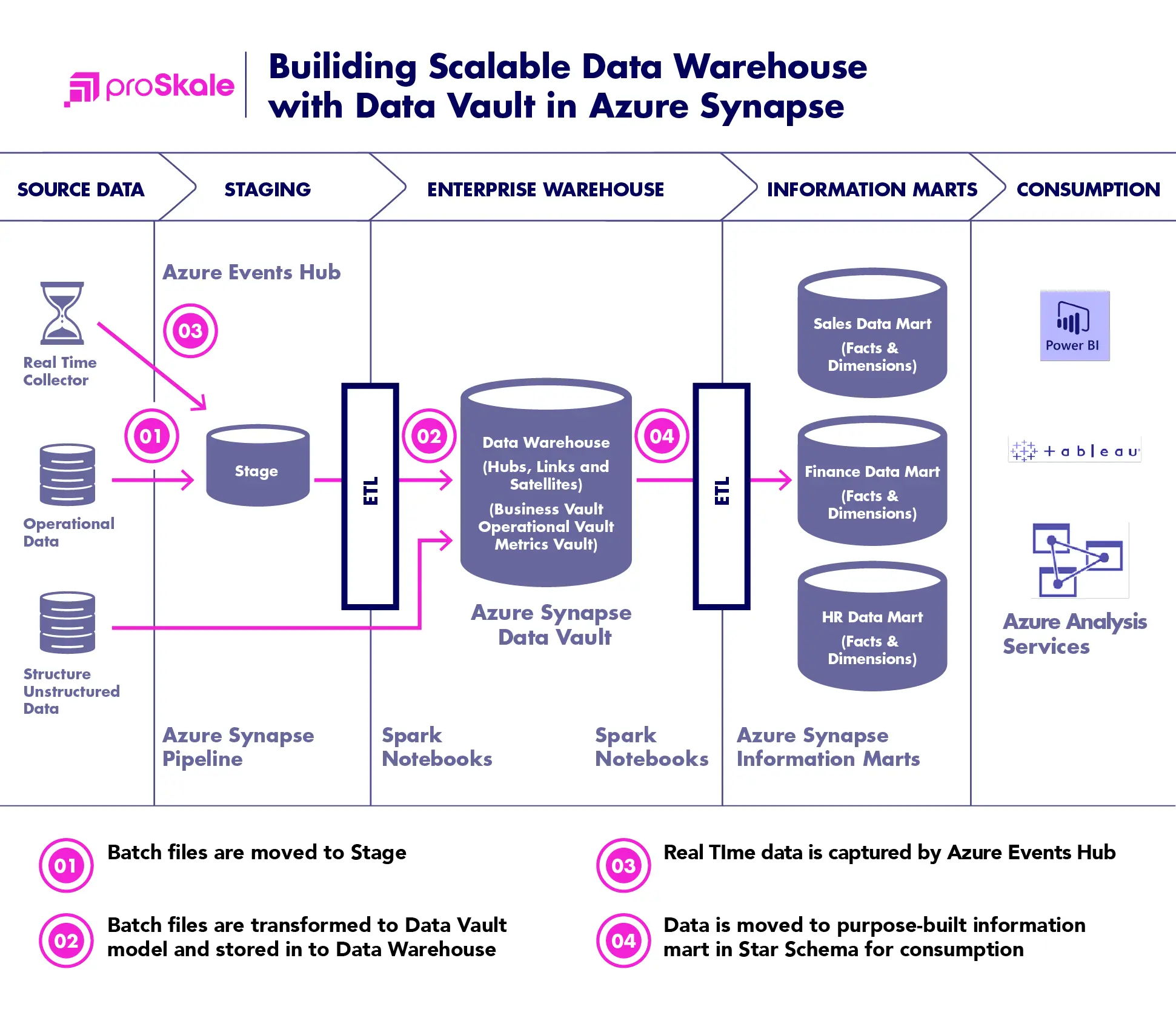
The Data Vault 2.0 architecture is based on three layers: the staging area, which collects the raw data from the source systems; the enterprise data warehouse layer, modeled as a Data Vault 2.0 model; and the information delivery layer, with information marts as star schemas and other structures.
The philosophy of Data Model 2.0 goes beyond data modeling:
- It is based on three pillars: methodology (CMMI. Six Sigma, etc.), architecture and model;
- It includes Big Data and NoSQL;
- It also focuses on performance.
Why Data Vault
- Dimensional modeling leads to a database design optimized for reporting and analytics.
- It becomes difficult to store data using dimensional models when business processes change.
- There is also the limitation of parallel loading of data when using dimensional models.
- There are performance issues when large volumes of historical data are processed in dimensional models due to sequential processing.
- Data Vault modeling optimizes the model for the flexible long-term storage of historical data.
- Data Vault simplifies data storage and their relationships to solve the problem of dealing with change in the environment by separating the business keys.
- Data Vault enables parallel processing and storage of data.
Why proSkale?
As your extended Solutions Center, we partner to remove barriers to scaling your transformational initiative-be it organizational or technical. Establishing the platforms and best practices that ensure adoption is achieved regardless of the delivery model, whether it’s an end-to-end solution, advisory or tactical implementation services.
- Experienced Data Modelers – One of the main challenges of designing the Data Vault implementation process is identifying business keys and designing Hubs, Links and Satellite tables. It requires highly skilled data modelers. proSkale data modelers have deep modeling experience in all different types of modeling techniques – normalization, dimensional and Data Vault’s Hub-Link-Satellites model.
- Automation of data processes – proSkale processes for data vault building and loading use automation to a large extent by using Azure Synapse that provides a powerful platform for implementing Data Vault 2.0.
- Extensive usage of templates – proSkale uses templates for building and populating the foundational structures of Data Vault 2.0 – Hubs, Links and Satellites.
- Integration of Azure Synapse pipeline with Spark – We automate the Azure Synapse pipeline to capture data and Spark notebooks. proSkale’s automation solution utilizes these tools.
- Metadata usage – proSkale leverages metadata in the automation of data vault processes.
- Parallelization of loading and transformation processes – we optimize the handling of big data for your specific scenario.