
Azure Data Factory (ADF) is a cloud-based ETL and data integration service that allows users to create data-driven workflows for orchestrating both data movement and data transformation.
- It is used to create and schedule data-driven workflows (called pipelines) that can ingest and transform data from disparate data stores.
- ADF can also publish transformed data to data stores such as Azure Synapse Analytics for business intelligence.
- It is a code-free ETL as a service on Azure.
ADF’s are built using Azure Resource Manager (ARM) templates, a decorative syntax that can create and deploy an entire Azure infrastructure. This allows for the intention of deployment to be stated, without having to write the programming commands, allowing ease when deploying to one or multiple resources like virtual machines and storage systems.
- It allows for repeatability, meaning you can deploy the same template multiple times with consistent results.
- ARM orchestrates the order of deployment for resources to ensure they are created in the correct order.
- You can deploy any Azure resource though the ARM template.
- There is built in validation ensuring success, and limiting the likelihood of unsuccessful deployment.
Following functions can be performed by Azure Data Factory:
Ingest – Data pipelines are used to move data from both on-premise and cloud sources to destination location.
Transform – The transform functionality of ADF is used to transform data. Data Flows are created to build data transformation graphs that are executed on Spark by ADF.
Publish – ADF can write transformed data in business-ready consumable form to destinations such as Azure Data Warehouse, Azure SQL Database, Azure Cosmos DB, and several others.
Monitoring – Monitoring can be performed on ADF console while pipelines are being executed.
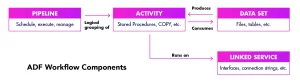
Components of ADF
- Pipelines – A pipeline is a logical grouping of activities that together perform a task.
- The activities in a pipeline define actions to perform on data.
- An Azure Data Factory or Synapse workspace can have one or more pipelines.
- Activities – Activities represent a processing step in a pipeline
- Datasets – Datasets represent data structures within the data stores, which simply point to or reference the data you want to use in your activities as inputs or outputs.
- Linked services – Linked services are much like connection strings, which define the connection information that’s needed for Data Factory to connect to external resources. Linked services are used for two purposes in Data Factory:
- To represent a data store that includes, but isn’t limited to, a SQL Server database
- To represent a compute resource that can host the execution of an activity.
- Data Flows – Represent data lineage.
- Integration Runtime – A linked service defines a target data store or a compute service. An integration runtime provides the bridge between the activity and linked Services.
- Triggers – Triggers represent the unit of processing that determines when a pipeline execution needs to be kicked off.
- Pipeline Runs – A pipeline run is an instance of the pipeline execution.
- Parameters – Parameters are key-value pairs of read-only configuration. Parameters are defined in the pipeline.
- Control Flow – Control flow is an orchestration of pipeline activities that includes chaining activities in a sequence, branching, defining parameters at the pipeline level, and passing arguments while invoking the pipeline on-demand or from a trigger.
- Variables – Variables can be used inside of pipelines to store temporary values and can also be used in conjunction with parameters to enable passing values between pipelines, data flows, and other activities.
Automation of ADF Pipeline Creation using Azure Resource Manager (ARM)
What is ARM – It is used to implement infrastructure as code for deploying Azure resources. Deployment is done through ARM Templates, a JSON file that defines infrastructure components and configurations.
Steps for Deploying ADH using ARM Template:
- Identify and document source and target data locations.
- Define infrastructure resources and configurations in a ARM template.
- Include the following resources in the template:
a. Data Storage account
b. Azure Data Factory
c. Data Factory Linked Services
d. Data sets
e. Pipelines - Deploy the template.
- Submit the template for execution and every successful completion.
- Verify that all resources are created.
- Create a Trigger for starting the Pipeline.
- Monitor.
- Verify the output file.
Summary
Azure Data Factory (ADF) is a SaaS resource from Azure. It is easy to use and can be used for data sources located both on-premise and cloud environments.