
The objective of this document is to provide a brief introduction of Dedicated and Serverless SQL Pools, part of Azure Synapse Analytics.
Azure Synapse Analytics is a data analytics service that includes all services that are required for ingestion, transformation, and visualization of data. It includes Spark Pool and SQL Pools for data analytics. There are two types of SQL Pools – dedicated and serverless.
Synapse analytical suite develops solutions for different data usage, in a way that allows predictability and cost efficiency no matter the consumption. Because of this, Microsoft developed two different types of data pools that handle different approaches to data management and compute scenarios.
The Serverless Data Pool is optimized for large-scale data with the compute in the pool being distributed and managed by Microsoft. There is room for configuration in structure and file format, with optimization for ad-hoc queries and exploratory data analysis.
The Dedicated Data Pool allows for more flexibility in how data is handled in a cost effective manner. It allows for multiple executions of the same or similar queries and automatic scaling without needing additional configuration.
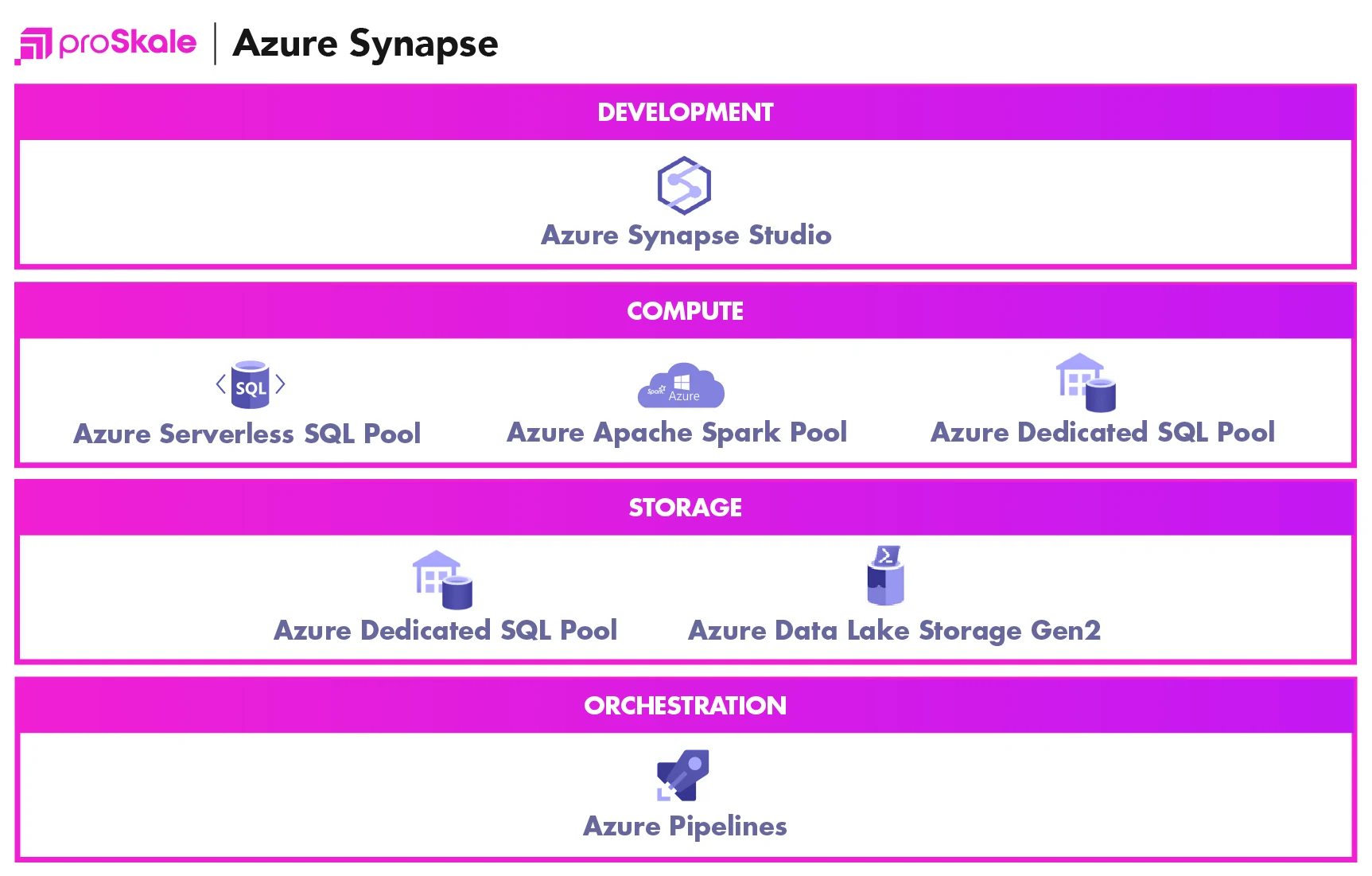
Dedicated SQL Pools
- Used for analyzing data loaded into Synapse internal tables.
- User-managed and can be any number per account subject to enterprise-wise limitations.
- Use fixed resources, not scalable.
- Contain all features of Enterprise SQL Data Warehouse.
- Its instance must be created and resources must be provisioned.
- Resources are measured in Data Warehousing Units (DWUs).
- A DWU is a combination of allocated CPU, Memory and IO resources.
- Number of DWUs determines query performance and cost.
- Users are charged for how long the dedicated pool is active, not number of queries executed.
- Can be paused and resumed.
- Data can be loaded into pool using COPY command.
- Node-based with query execution distributed across nodes.
- Advantages:
• No external table to define.
• Storage of data in relational format, so better performance and less storage.
• Storage is charged separately, independent from compute power.
• Stores a table as Clustered Column store index by default.
◦ This storage format achieves high compression and better query performance on large table.
◦ Partitioning of data is supported.
Serverless Pools
- Act as a query service over data in Azure Data Lake through an ‘external table’.
- Does not require any extra configuration; it is used as Software as a Service (SaaS).
- User does not have to set up infrastructure; it is provided by Azure.
- The OPENROWSET function of T-SQL is used for querying data.
- User pays for the amount of processed data.
- Create statistics that are reused for multiple execution of the same query or queries with a similar query execution plan.
- Enable querying of large volumes of data directly from Data Lake.
- Use external table for SQL query execution.
- Azure allows only one serverless pool per account.
- Azure automatically scales the serverless pool depending on processing requirement.
- There are no fixed resources linked to it.
- Default option in Synapse workspace for SQL pools.
- Node-based and query processing is distributed across nodes.
- Can process parquet, ORC, Delimited text formats of data.