We’re laser focused on scaling your AWS environment, regardless of the delivery model, whether it’s an end-to-end solution, advisory or Consulting. From automating key processes, implementing our accelerators and frameworks to delivering entire platforms.
Why choose us?
- proSkale’s data ingestion process is cheaper and faster. It can be an ideal choice for data migration from on-prem to cloud, especially between relational databases. The process is built in automation and is event driven.
- proSkale’s trained staff provides a turnkey solution which also includes training and post implementation support.
- proSkale can create customized serverless solutions to fit customer needs.
- proSkale engineers first do a thorough analysis of customer on-prem infrastructure prior to designing, developing and implementing a serverless process.
Why should you choose AWS?
Data processing needs are constantly evolving, and the need for faster intake and analytics of structured, semi-structured and unstructured data is growing every day. A serverless data lake on AWS does not require any server, databases or any other hardware and software to be configured. AWS provides services as SaaS, which are charged on a ‘pay-as-you-use’ basis.
- No upfront hardware or software configuration required
- 24/7 availability
- Auto scaling & Event driven
- Requires minimal maintenance; users can focus on delivering business objectives instead of getting entangled in day-to-day operational activities.
- proSkale has developed its own fully automated event-driven data migration process that can extract and load data from all popular relational databases, Teradata, Oracle, SQL Server etc., to AWS S3, Redshift, relational databases and Snowflake.
Whether it’s surgically fitting into one narrow need or across your entire Data Lake Architecture, we’re here to empower your team in its Cloud journey.
Whether it’s surgically fitting into one narrow need or across your entire Data Lake Architecture, we’re here to empower your team in its Cloud journey.

What aspects of this architecture are unique to proSkale’s approach?
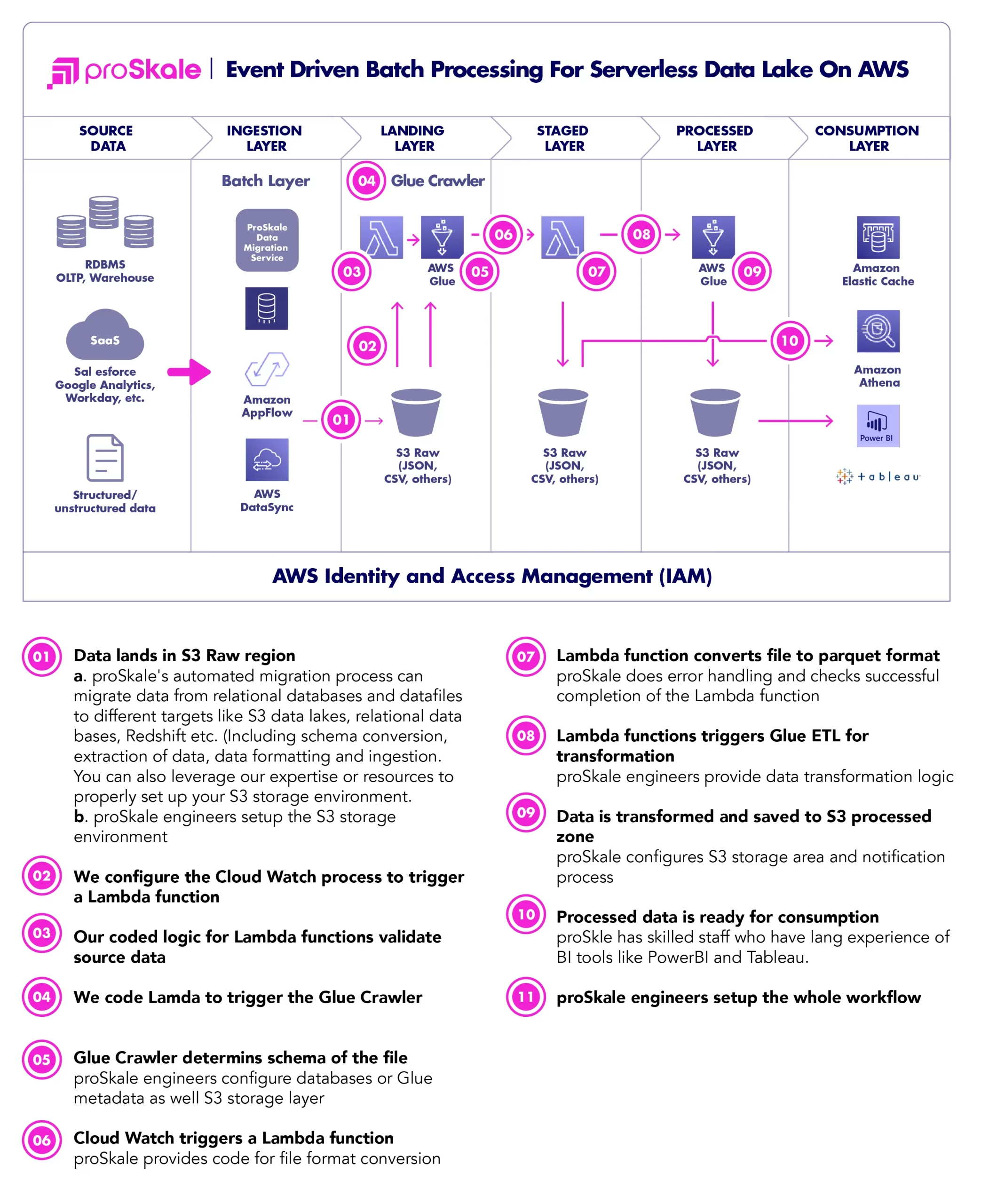
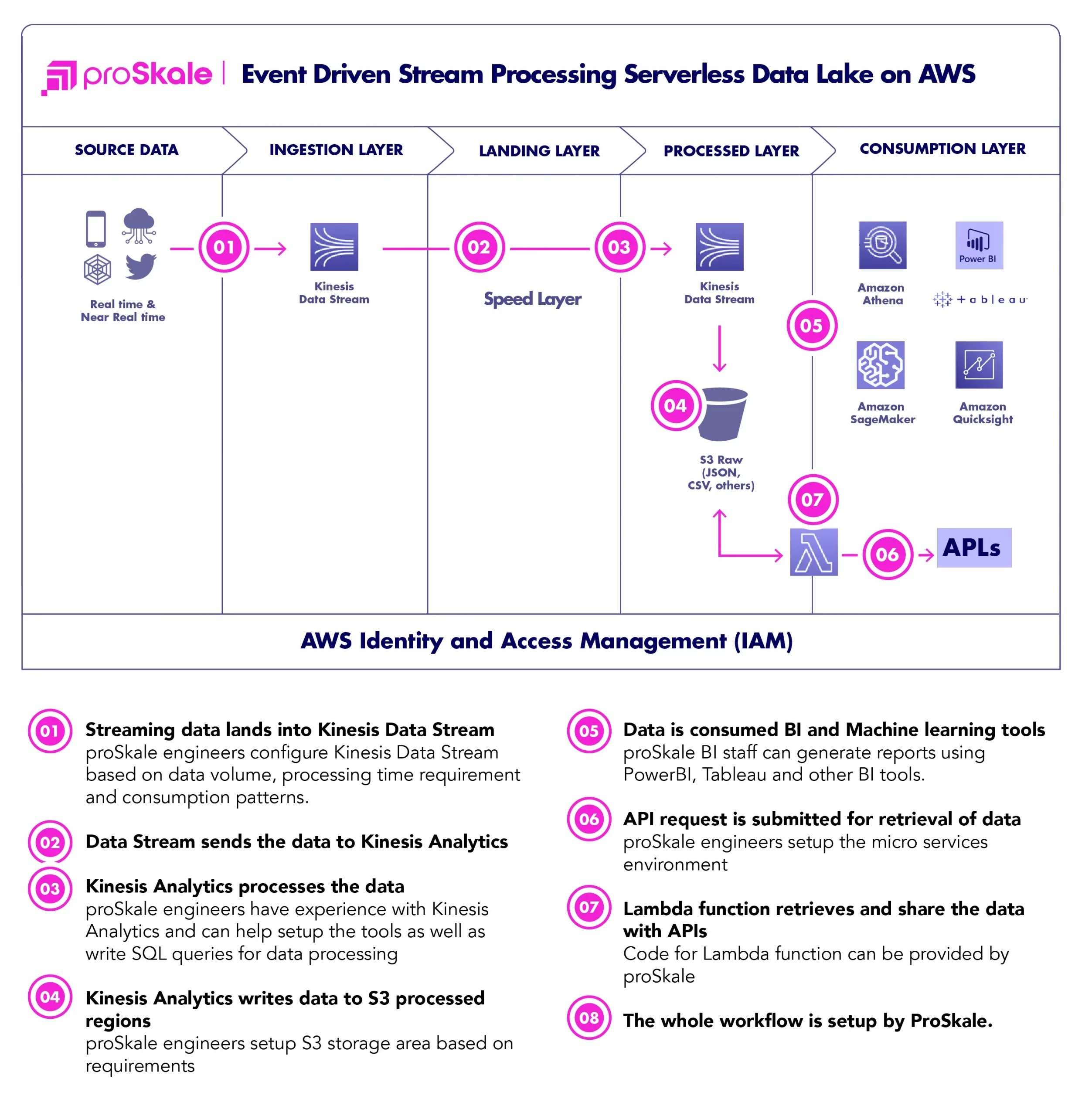
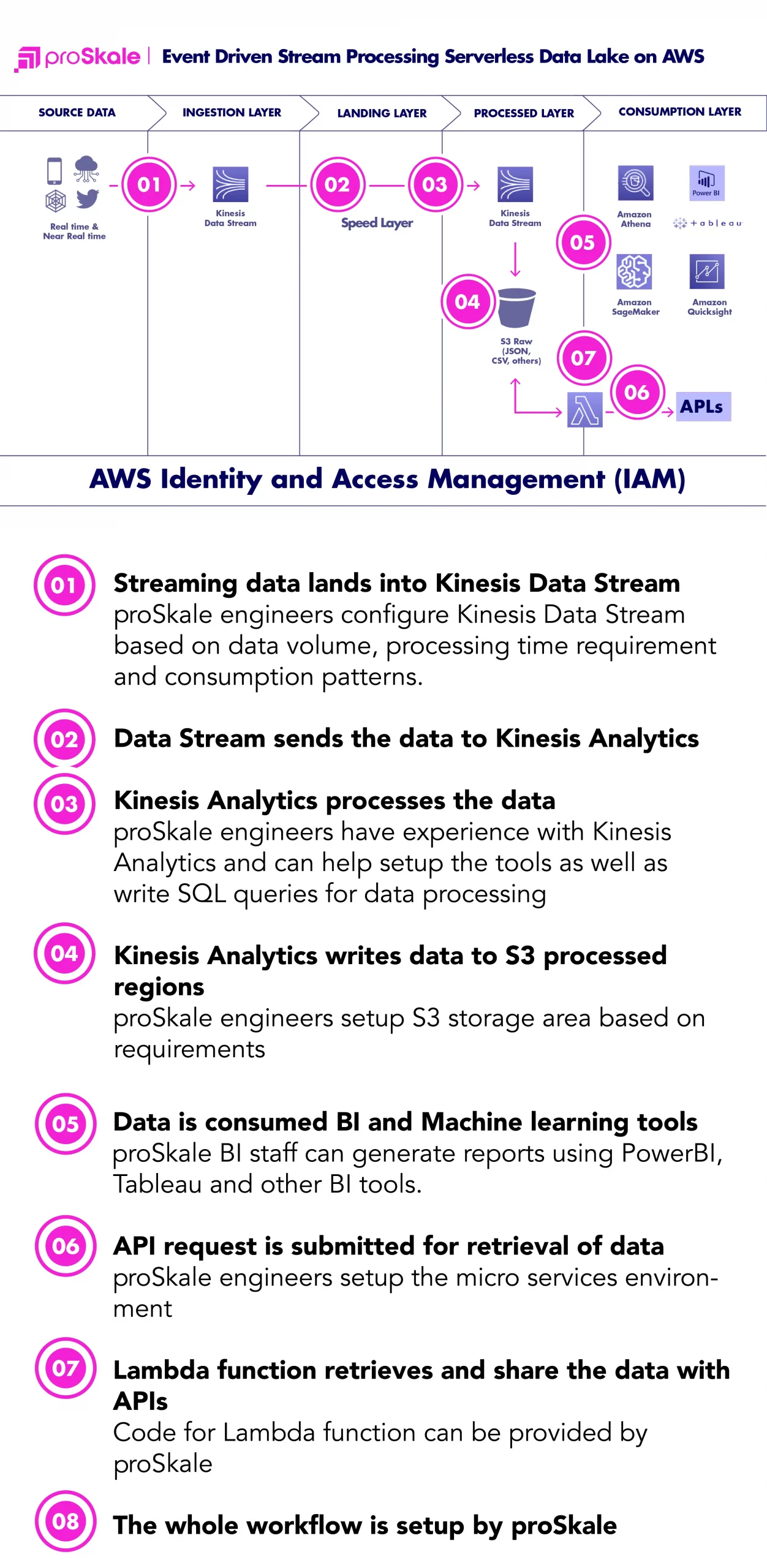
It supports both batch and real-time data processing.
This architecture includes proSkale’s own event driven data migration process that can be customized. It is proven process that saves data migration cost and time
ProSkale’s Serverless Data Lake solution on AWS, supports both batch and real-time and near real-time data ingestion, transformation and analytics.
Batch Mode
- There are a variety of tools available to put source data into Amazon S3. ProSkale has its own data migration tool to migrate relational databases and batch files to Amazon S3, relational databases, Redshift and also Snowflake.
- Once data lands in S3, AWS Lambda functions if started through Amazon Cloud Watch.
- Lambda function starts an Amazon Glue Crawler that determines the schema of the source file.
- The Glue Crawler updates the database with metadata of the file.
- A lambda function is started once the Glue Crawler job is completed. It validates the source data and converts it to parquet format and writes in another S3 bucket called ‘stage’ .
- A Glue ETL job is started once the data is fully loaded into S3 Stage.
- The Glue ETL job transforms the data and moves transformed data to S3 Processed bucket for consumption.
- The Glue ETL jobs sends an email notification through Amazon SNS (not shown the in the diagram above)
Speed Mode
- Real-time data is processed through Amazon Kinesis Data Stream.
- It feeds Amazon Kinesis Analytics for data transformation.
- The Amazon Kinesis Analytics writes processed data into S3 through Kinesis Firehose(not shown in the diagram above).
Benefits
Pros
- No need to worry about purchasing, provisioning, and managing backend servers
- Cheaper: ‘pay-as-you-go’ model only charges for what services are used and for how long.Reduced resource and labor cost
- Scales automatically
- No maintenance needed
- Faster to deploy: no need to migrate code to servers
- Faster time-to-market
- Event-driven automated process
- Extremely good for processing streaming data
- Has implicit high availability
Cons
- Not suitable for long running processes
- More reliance on cloud providers – infrastructure is taken care of by providers.
- Loss of control for configuration, performance, security, support
- Shared infrastructure
How is the ROI determined? What factors are needed to make a Business Case? How can proSkale help to get a project started?
After thorough analysis of the existing on-prem applications, proSkale’s engineers design a serverless system that includes cost and cycle time. These metrics are used to determine ROI. proSkale’s solution generally saves 40% to 50% over on-prem cost.
ProSkale can do a POC to show cost and time savings. Based on the result of the POC, the customer can decide whether to move forward with proSkale’s solution.
From a business perspective – how do customers benefit?
Benefits for customers include lower operational cost, no infrastructure cost, very low maintenance cost, faster time-to-market and ability to scale the environment in a very short period. Amazon AWS provides automatic scaling. ProSkale ensures that their solution meets regulatory compliance requirements and provides security through AWS’s proven security tools like Identity and Access Management, encryption, role-based access control and multi-factor authentication. The solution captures metadata of the ingested data, thus preventing the Data Lake from becoming a ‘Data Swamp’.
Why consider a Serverless Data Lake on AWS?
A serverless data lake architecture’s primary advantage is the ability to store objects in a highly durable, secure, and scalable manner with only milliseconds of latency for data access. A serverless solution provides the ability to load any type of data – from web sites, business apps, and mobile apps to even IoT sensors.
Serverless architectures offer greater automation and scalability, more flexibility, and quicker time to market, all at a reduced cost.
Compared to other cloud-based data lake solutions, serverless data lake enables lower latency for data life cycle; data is processed in milliseconds as soon as it is generated.
A serverless data lake solution can also handle small, medium and large files, which is done by splitting large files into smaller files and processing each file in separate serverless job streams running in parallel.
What are the challenges & opportunities that a Serverless Data Lake on AWS can address?
- A Serverless Data Lake provides very low latency for data processing. Data from generation to consumption may take a few seconds when using serverless—much less than when using IaaS framework.
- Infrastructure setup takes time and requires operational support, which a serverless solution bypasses for faster time-to-market.
- With an IaaS solution, the customer pays for the whole infrastructure, in contrast to the much less costly ‘pay-as-you-go’ serverless model.
What is unique about proSkale’s approach?
- proSkale’s proven solution of automating the data processing lifecycle enables millisecond latency for the whole lifecycle of data processing—capture to consumption.
- More automation with less manual intervention enables self-service for data scientists and analysts. It also results in savings in terms of time spent on operational support for non-serverless (IaaS) data processing solutions.
- It enables faster time-to-market and fits well for transaction fraud, gathering customer insights, IOT data processing, near real-time data acquisition and transformation in addition to batch mode of data ingestion and processing.
What does the Tech Stack look like?
- proSkale’s Data Migration Tool – proSkale has developed a data migration tool that does schema conversion between disparate source and target relational databases. The process is parameter-driven and is easy to customize. It is used for both bulk load and incremental loads.
- Amazon S3 – Data Lake storage. It can store almost all formats of data – structured, unstructured and semi-structured.
- Amazon Lambda – A serverless tool to execute user written functions in Python, Java and several other programming languages
- Amazon Glue Crawler – Glue Crawlers are used to determine metadata of the source data. It updates the newly found metadata to Glue Catalog and can recognize metadata for a variety of file formats such as CSV, JSON, Parquet etc
- Amazon Glue ETL – It is used to transform input data into desired output format and in the process, it can transform data formats.
- Amazon Athena – Used for executing SQL queries on structured and semi-structured data on S3.
- Micro-services using Lambda Function – Used to support API calls. APIs trigger a pre-configured Lambda function to query and update data on S3.